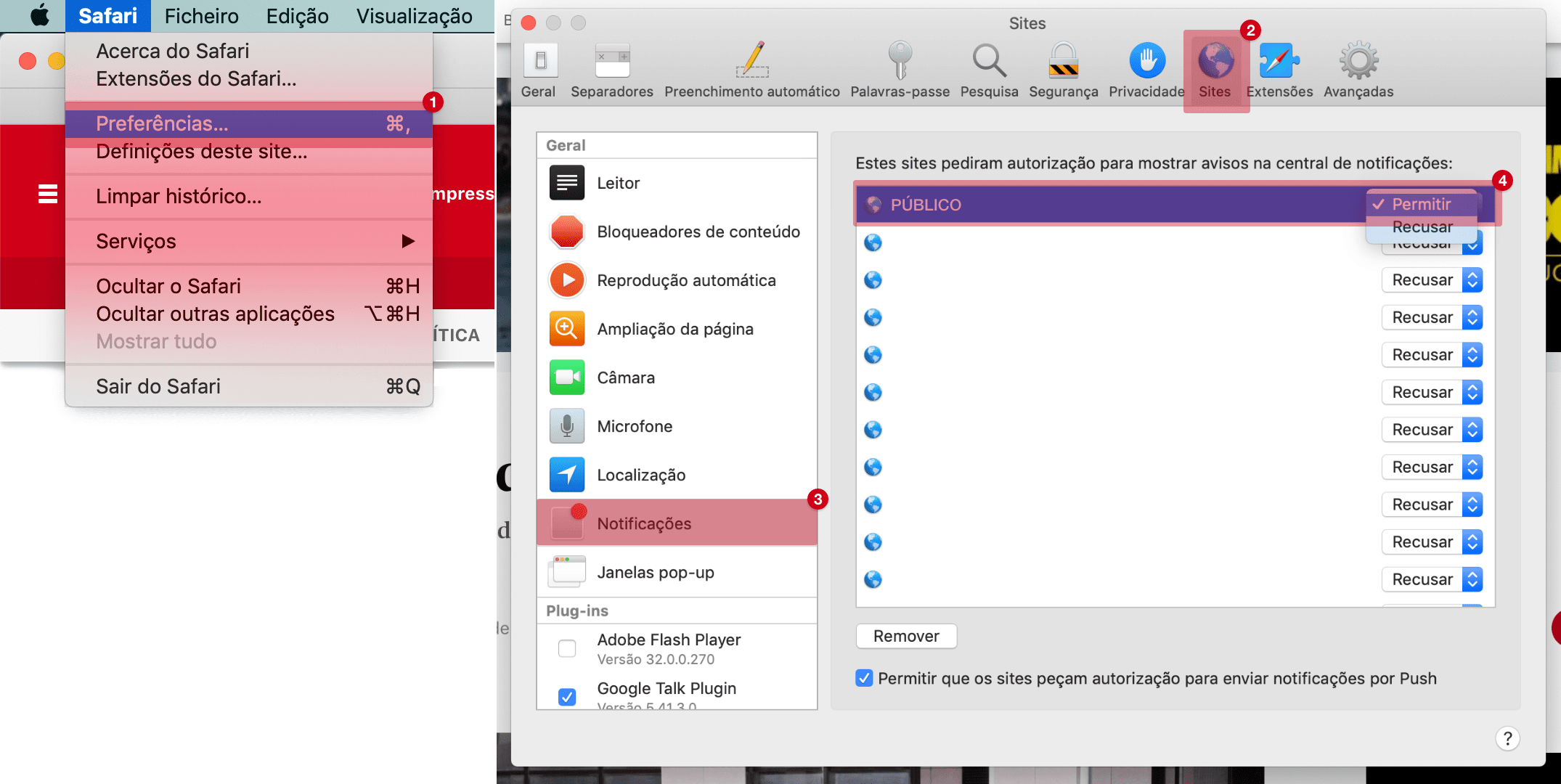
Inteligência artificial aprende sozinha a ser a melhor do mundo no Go
Tecnologia foi criada pela DeepMind, uma empresa do grupo do Google. O sistema treinou contra si próprio ao longo de 29 milhões de jogos.

Um programa de computador aprendeu sozinho a tornar-se no melhor do mundo naquele que é um dos mais complexos jogos de tabuleiro de sempre, descobrindo, em poucas semanas, conhecimento que os humanos criaram e acumularam ao longo de mais de 2000 anos.
A DeepMind, a empresa de inteligência artificial do grupo do Google, desenvolveu uma nova versão do AlphaGo, o programa com que já derrotou dois campeões humanos de Go, um milenar jogo com uma forte tradição na China. Esta nova versão não só foi capaz de derrotar as anteriores, como aprendeu as melhores jogadas tendo apenas como conhecimento de partida as regras do jogo. O resto foi descoberto ao fazer milhões de jogos contra si própria.
A explicação do desenvolvimento da nova versão do Alpha Go foi publicada na revista científica Nature. O feito é mais um passo no caminho da criação de algoritmos capazes de aprender qualquer tipo de tarefa, desde que tenham a informação necessária – e capazes de se tornarem melhores do que os humanos a executá-las.
“Um objectivo antigo da inteligência artificial é um algoritmo que aprenda, tabula rasa, a ter uma proficiência sobrehumana em domínios complexos”, escreveu a equipa da DeepMind no artigo agora publicado. “Começando tabula rasa, o nosso novo programa, Alpha Go Zero, alcançou um desempenho sobrehumano.”
No Go, os dois oponentes usam as respectivas pedras para tentar obter mais território no tabuleiro do que o adversário. O número de jogadas possíveis é muito superior ao do xadrez, onde os computadores já derrotam os humanos há anos. Para que o sistema de inteligência artificial aprendesse, os investigadores indicaram à máquina apenas as regras e o objectivo do jogo. Sem qualquer conhecimento sobre estratégias e técnicas, o computador começava por jogar de forma aleatória e ia aprendendo quais as melhores jogadas. A versão mais poderosa do AlphaGo Zero fez 29 milhões jogos contra si própria, ao longo de cerca de 40 dias.
Aprender através de milhões de jogos significa uma curva de aprendizagem diferente da dos humanos. O equipa da DeepMind notou que um dos elementos do jogo que é ensinado aos humanos logo no início só foi descoberto pela máquina numa fase muito mais tardia.
A capacidade do AlphaGo Zero foi depois testada num torneio contra outros sete jogadores com inteligência artificial, incluindo versões antigas do AlphaGo e programas de computador usados por humanos para jogar e treinar. Também disputou uma partida mais longa apenas contra uma versão mais antiga. O novo sistema não foi imbatível, mas foi o mais bem classificado na competição.
A ideia de fazer com que programas de computador aprendam sozinhos (a chamada aprendizagem automática, ou machine learning) é uma das áreas da inteligência artificial que tem suscitado mais atenção, tanto por parte da academia como das empresas. Recentemente, o Facebook criou programas de computador para que aprendessem a negociar uns com os outros e estes acabaram por desenvolver uma linguagem própria (um efeito secundário que não é inédito neste género de experiências). A DeepMind também já tinha criado agentes de inteligência artificial que aprenderam sozinhos a correr (alguns tinham uma estrutura semelhante à de um humano, outros assemelhavam-se a aranhas) e a ultrapassar obstáculos.
“Os nossos resultados demonstram cabalmente que é possível uma abordagem de pura aprendizagem por reforço, mesmo nos campos mais complexos", concluíram os investigadores. "É possível treinar até um nível sobrehumano, sem exemplos ou orientação humana, e sem nenhum conhecimento para além das regras básicas.”